 Blogf
BlogfCe blog est encore en construction
CR de la conférence Guide de survie pour créer son authentification à l’intention des développeurs
- Conférence : DevFest Strasbourg 2024
- Speakers : Marine Du Mesnil et Paul Molin
- Lien vers la video : Youtube
- Publié le : 14 Décembre 2024
Quelques mots sur la conférence et le talk
Le DevFest Strasbourg se décrit comme “La plus grande conférence technique du Grand Est destinée aux développeurs”.
Ce talk parle d’authentification (authN), et les auteurs font bien la distinction avec l’authorisation (AuthZ) qui ne sera pas l’objet du talk (spoiler: un peu quand même). C’est à dire qu’on va parler de ce qui prouve qui je suis mais pas de ce qui décide de ce que j’ai le droit de faire.
Les deux speakers travaillent chez Theodo, et sont tous deux experts en cybersécurité. Marine Du Mesnil est d’ailleurs responsable de la cybersécurité applicative, Paul Molin est group CISO.
La cybersécurité, rappels sur les moyens d’authentification
Quand on pense sécurité, on pense en premier lieu aux mots de passe. Rappelons-le, ceux-ci doivent être hashés: une opération à la fois irreversible et sans collision possible. Par contre, cela ne suffit plus car avec une simple table de correspondances (rainbow tables) on peut facilement retrouver des mots de passe à partir des valeurs hashées. Pour contrer ça, on ajoute du sel (une chaine de caractères aléatoire) au mot de passe, pour permettre de le différencier des autres mots de passe similaires. Là encore, cela ne prémunit pas totalement non plus, avec du brut force sur une base il est toujours possible de retrouver cette valeur.
Pour y rémédier entrent alors en jeux les algorithmes modernes (Argon2, scrypt, bcrypt, PBKDF2) qui ont deux caractéristiques :
- ils sont lents (en tout cas suffisamment pour éviter le brutforce)
- le sel va être contenu dans l’output de l’algorithme donc pas besoin de le stocker en base et le rendre comprométable
Le résultat de l’output contient toutes les informations utilisées pour générer ce mot de passe. On peut donc, en plus, s’en servir pour regénérer des hashs différents si besoin (plus sécurisés par exemple) de manière transparente pour l’utilisateur.
Généralement, les hackers ne persistent pas quand ils sont ralentis dans la récupération de mots de passe et se concentrent plutôt sur des solutions simples et rapides. Notamment, lorsqu’ils récupérent des couples login / mot de passe dans une fuite de données. Ils vont généralement faire du spoofing, c’est à dire aller vérifier dans d’autres applications (via des bots) si ces couples ne sont pas réutilisés et s’en servir.
Pour s’en prémunir (en plus, pour les utilisateurs, de ne pas réutiliser de couples email / mots de passe), la première chose à faire c’est d’utiliser le multi-facteur (MFA), c’est à dire combiner plusieurs moyens d’authentifications :
- ce que je sait: un mot de passe, code pin...
- ce que je suis: une empreinte digitale, reconnaissance faciale...
- ce que j’ai: une ubikey…
Dans la peau d’un attaquant
Un des moyens les plus fréquents de compromettre la sécurité pour un attaquant c’est d’injecter des scripts javascript malveillants dans une application. Et il existe plein de façons de faire:
- via les dépendances (librairies), notamment lorsque des backdoors sont introduites dedans
- via les scripts externes de la même manière, notamment lorsque le script est abandonné et repris par des gens malveillants
- via les entrées utilisateurs, lorsque le xss n’est pas maîtrisé
- via le contenu externe, par exemple des images
Généralement l’attaquant va s’en servir pour accéder aux informations de l’utilisateur, qu’elles soient dans les cookies ou le local storage.
Les cookies sont une chaîne de caractère envoyée par le serveur et stockée dans le navigateur. On peut par défaut afficher tous les cookies rattachés à une page web (document.cookie). Par contre, on peut restreindre leur accès aux requêtes HTTP (et donc ne pas le rendre vulnérable aux failles XSS) en forcant l’attribut httpOnly à true.
Ce n’est pas valable pour le localStorage dont les informations sont accédées via javascript (donc on ne peut pas l’interdire). La solution qui a été trouvée est de rendre la session dans le local storage accessible sur une durée très courte (une dizaine de minutes) donc si l’attaquant vole la session il sera limité. On va associer ça à un refresh token qui lui sera stocké dans un cookie (et ne pourra pas être récupéré en javascript).
Bon par contre, s’il y a une faille XSS dans notre application, l’attaquant ne pourra peut-être pas voler le cookie mais il pourra faire des requêtes avec car le navigateur envoie par défaut directement le cookie dans les requêtes. On est quand même fichus, il est donc toujours important de corriger les failles XSS de notre application !
D’ailleurs, même les cookies ne sont pas la solution ultime, peu avant la conférence, des attaquants ont réussis via un malware à récupérer des cookies.
Réagir en cas d’attaque
Persister ou non les sessions
Dans cette partie on va introduire la notion de stateful et stateless, c’est à dire est-ce que le serveur a connaissance de l’état de l’authentification. J’aime bien l’analogie de l’entrée dans une soirée privée, où l’on rentrerait soit avec un carton d’invitation soit via une liste à l’entrée.
Dans le cas du stateful, le serveur va vérifier l’information fournie par l’utilisateur, par exemple son cookie avec sa session envoyé dans la requête http en la comparant avec ses informations en db.
Dans le cas du stateless, pas besoin de vérification en db, l’utilisateur porte directement son identification dans son token (JWT). Le serveur va se contenter d’en vérifier les informations, c’est à dire, s’il est expiré, si l’issuer et l’audience (donc l’application pour lequel il a été généré) sont valides. Pour rappel, un token JWT comporte 3 parties: le header avec les paramètres du token, ensuite la charge utile avec les claims, puis la signature qui sert à s’assurer que le reste du token n’a pas été falsifié.
Reprise du contexte initial: comment réagir quand la session d’un utilisateur a été volée ?
- dans le cas d’une session stateful, il suffit d’invalider la session de l’utilisateur
- dans le cas d’une session stateless, c’est beaucoup plus difficile. Ce qu’on peut faire c’est changer le secret, ce qui va invalider la session lors du prochain appel. Néanmoins, l’impact est important car ce secret n’est pas uniquement celui de l’utilisateur mais de tous. Par conséquent on va invalider la session de tous les utilisateurs.
Et comment réagir dans le cas d’une attaque MITM (man in the middle) ? Dans ce cas on va de toute façon toujours privilégier l’utilisation d’HTTPs donc activer l’option secure dans nos cookies, en plus du httpOnly.
Cela permet de prévenir la récupération des cookies mais pas forcément le fait de pouvoir les utiliser. Pour rappel, comment marchent les cookies: je me connecte sur un site avec authentification et je récupère un cookie après m’être authentifié. Ensuite mon navigateur va automatiquement envoyer ce cookie lors de toutes les requêtes sur le site.
Que se passerait-t-il si j’allait sur un site qui va de manière malicieuse faire des appels sur ce site où je m’étais précédemment connecté et en profiter pour récupérer mon cookie au passage ? On appelle ça une attaque CSRF (cross-site request forgery) et on aimerait bien s’en protéger. Une des solutions (il en existe pleins), c’est d’utiliser une option built-in des cookies: l’option same-site.
L’attribut same-site peut prendre 3 valeurs :
- None: pas de restriction sur le same-site, pas safe
- Lax: envoyé dans certains cas
- Strict: le cookie n’est jamais envoyé
Mais d’ailleurs, qu’est-ce qu’un “same site” ? La règle c’est que les sites doivent provenir du même domaine.
www.theodo.fretapi.theodo.fr✅ (same site/domain)www.google.cometgoogle.com✅ (same site/domain)owasp.github.ioettop10.owasp.github.io✅ (same site/domain)theodo.execute-api.ap-east-1.aws.cometowasp.execute-api.ap-east-1.aws.com❌ (pas same site/domain)
NDLR: attention à THE LIST, une liste publique de suffixes dont les sous-domaines fonctionnent différemment.
Si on applique toutes les options évoquées sur notre cookie on obtient ça :

Les services d’authentification tiers
On peut aussi passer par des services d’authentification tiers (Identity Provider ou IDP) comme OpenId Connect (un protocol d’authentification), une surcouche d’Oauth2 (qui lui est un protocole d’authorisation).
Les acteurs de l’authentification dans ce cas sont :
- l’utilisateur
- l’application (le client)
- l’Identity Provider (aka IDP)
- les API que le client va requêter pour le compte de l’utilisateur
Par exemple dans le cas d’un outil (B) qui va accèder à un autre outil (A) pour le compte de l’utilisateur, plutôt que de demander à l’utilisateur de s’authentifier via login/mot de passe on va délèguer l’autorisation. Pour cela, l’utilisateur va être invité à s’authentifier sur le service dont il souhaite la délégation (A), et va récupérer en échange un PAT (Personal Access Token) qu’il va saisir dans l’outil a qui il souhaite donner la délégation (B).
Par contre c’est un peu laborieux pour l’utilisateur, on va donc plutôt utiliser le système des redirections.
- L’utilisateur se connecte à l’outil B
- Celui-ci le redirige (302) vers l’outil A (cela passe par son navigateur)
- L’utilisateur s’authentifie sur l’outil A et donne son consentement
- Il est ensuite redirigé (302) vers l’outil B avec un access token en query param (et d’autres informations notamment des scope, une redirect uri, etc.)
- L’outil B peut désormais se servir de l’access token pour utiliser l’outil A a la place de l’utilisateur
Ce flux s’appelle l’Implicit Flow et on va préciser dans l’URL monurl/authorize?response_type=token
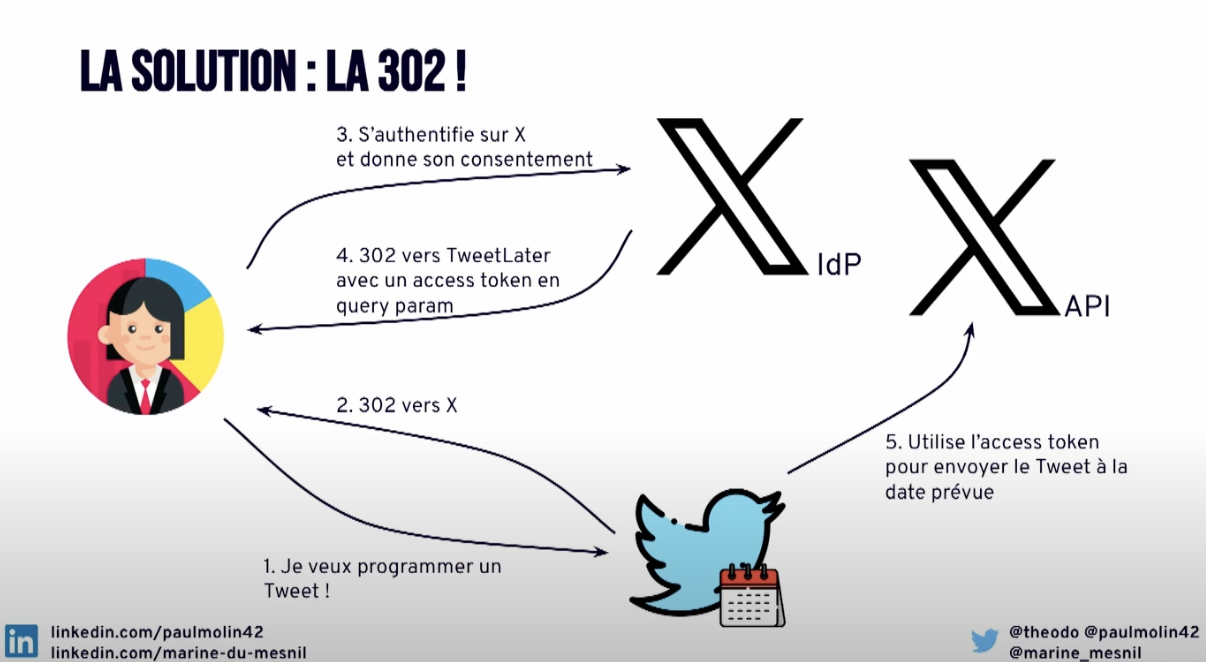
Mais que se passe-t’il si un attaquant forge cette url et incite un utilise à aller dessus, avec une redirect uri redirigeant vers une page à lui ? Parce qu’a priori l’utilisateur va réaliser tout le flux (étapes 1 et 2) et l’attaquant pourra récupérer toutes les infos en query_param.
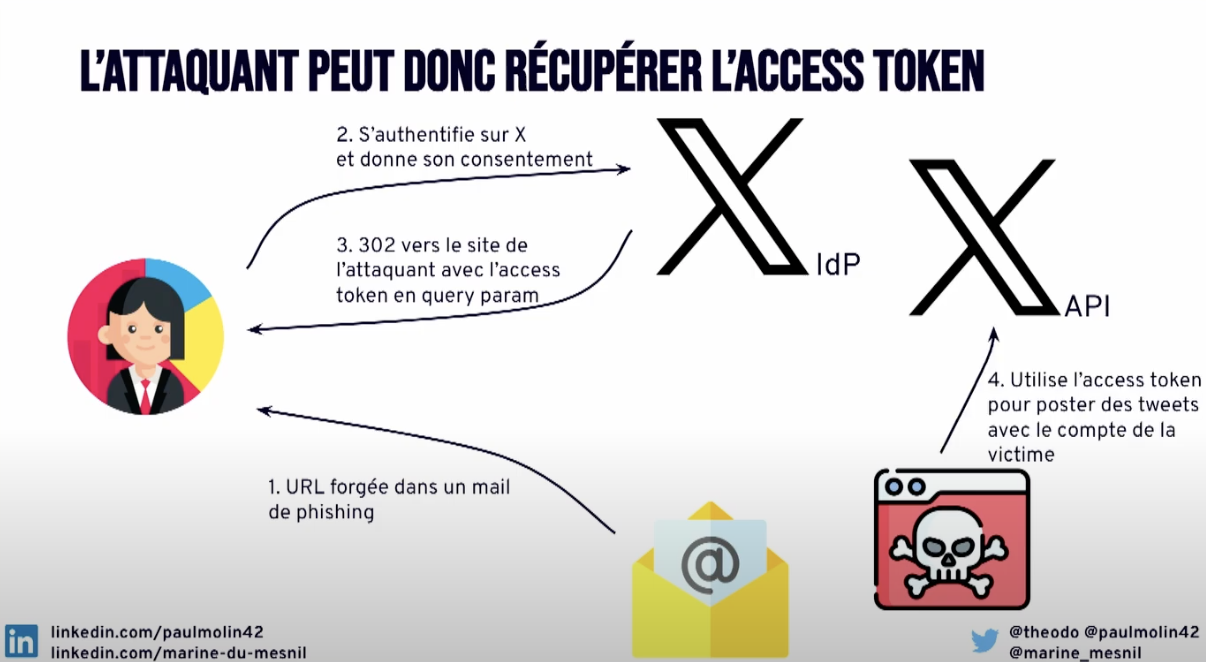
Heureusement la solution est relativement simple. Les développeurs de l’application A vont définir une liste de redirect uris autorisées. Si l’URL ne figure pas dans la liste, l’action sera rejetée dès l’étape 2.
Il reste quand même possible de récupérer le token, par exemple via une application malware sur le mobile, une extension navigateur… Donc on préfererait éviter de faire transiter cette information (le token) par l’URL.
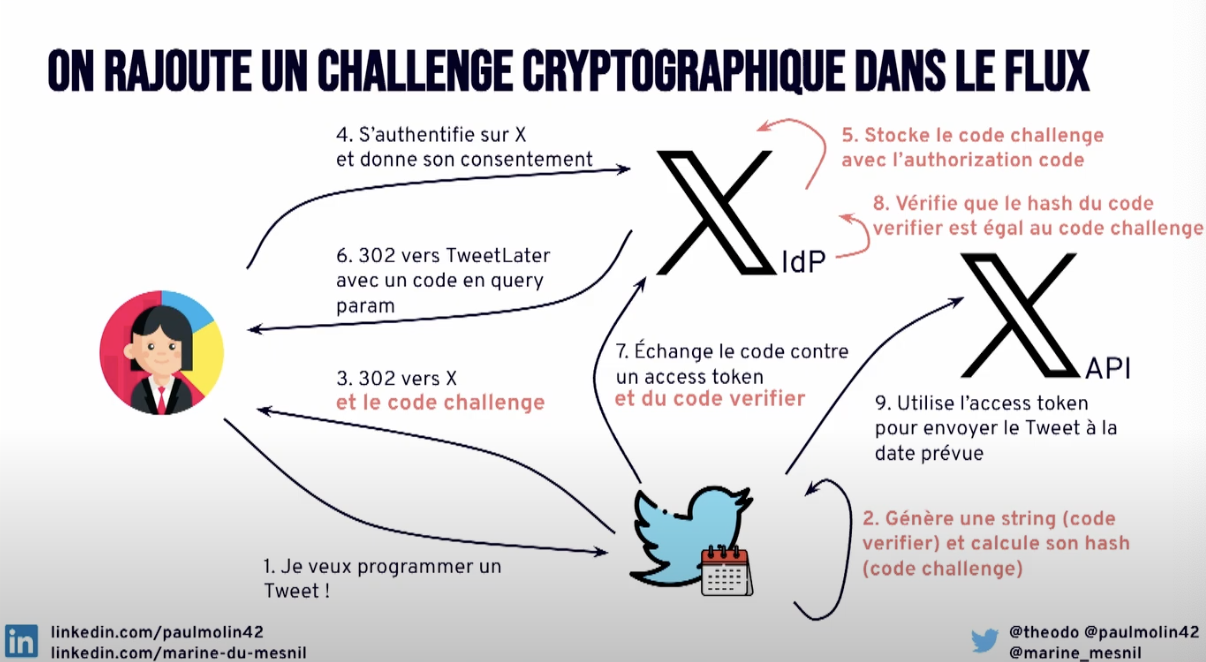
Pour ça on pourrait par exemple passer par un code, que l’application B utiliserait ensuite pour demander un access token auprès de A.
Ca s’appelle l’Authorization Code Flow et pour l’utiliser on va préciser monurl/authorize?response_type=code
Selon que le client est côté navigateur ou côté serveur, le comportement pour se prémunir des interceptions sera différent.
Dans le cas d’un fonctionnement backchannel donc serveur à serveur on va se servir d’un secret connu des deux mais invisible du reste du monde.
Si on est côté navigateur donc frontchannel, on pourrait aussi utiliser un secret mais il serait accessible de tous. On va donc intégrer en plus un challenge cryptographique dans le lot qui servira de clé de vérification par la suite. On appelle ça le flow PKCE (Proof Key Code Exchange) et cela permet de vérifier que l’application qui fait la demande d’échange entre l’access token et le code (étape 7 ci-dessous), est la même que celle qui a initié le flux à l’étape 3.
L’access token :
- est Bearer: il se suffit en soi pour donner des accès
- il donne accès aux APIs
- il peut être opaque
- il peut ne contenir aucune information sur l’utilisateur
Le passage de l’autorisation à l’authentification
On a évoqué OIDC précédemment. Pour passer d’Oauth2 à OIDC on va utiliser des scopes réservés: openid, email ou profile et introduire un id token
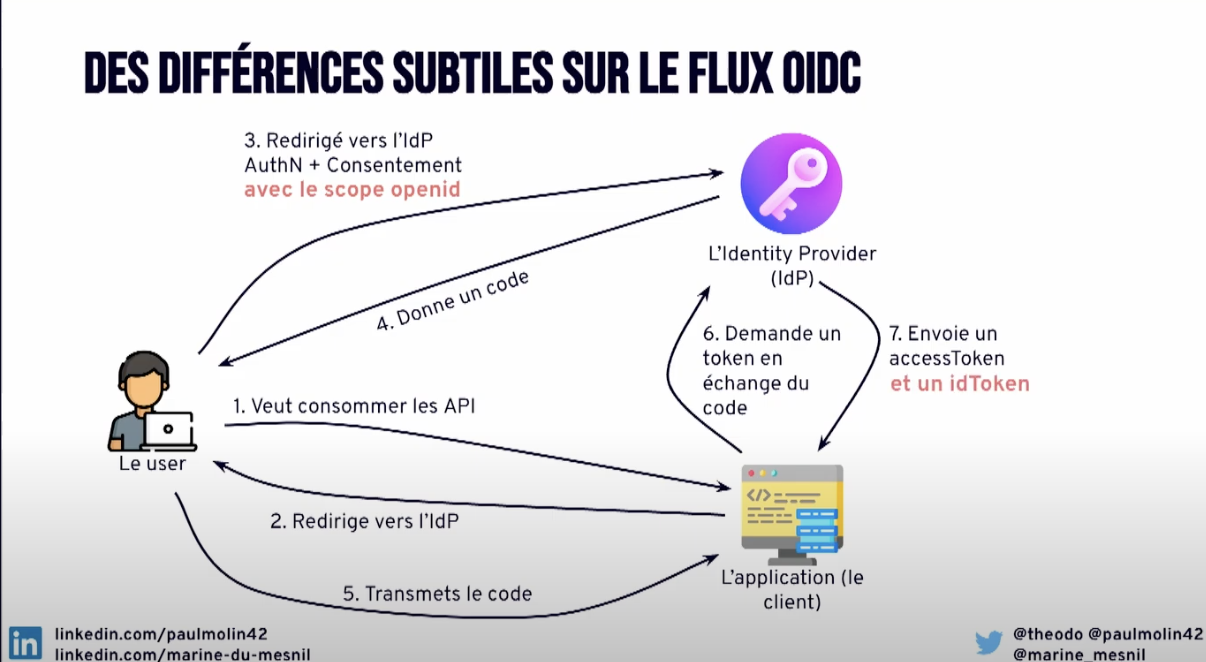
L’id token :
- est Bearer: il se suffit en soi pour donner des accès
- ne donne accès à rien, il va permettre d’identifier
- il va contenir des informations, c’est un JWT, selon le scope indiqué
- il contient des informations sur l’utilisateur